LLM Architecture and NLQ Flow
Intended audience: DEVELOPERS ADMINISTRATORS
AO Platform: 4.3
How Does the Process Flow Work?
Pre-Processing
The objective is to clean up the text (question entered by the user in Easy Answers) by removing words before sending the remaining words to LLM Token Identification.
When an NLQ comes into our system, we start with pre-processing steps which include stop word removal (eliminate words that are so widely used that they carry very little useful information), identifying abbreviations, incorrect spellings, punctuations, etc.
Then there is a Named Entity Extraction (a natural language processing (NLP) technique that identifies and classifies specific data points in text. NER can help machines extract valuable information from large amounts of unstructured text. The goal of NER is to streamline information extraction tasks, such as identifying key information and sorting and ranking pieces of information by importance.), and Address Extraction which identifies entities like organizations, names, places, zip codes, street names, etc.
Token Identification
There are 2 Objectives: a) Mapping tokens(words) to the Graph DB i.e., Arango DB (Ontology, MSO, Value Synonyms, and Rule Synonyms), and b) identifying and understanding the meaning of the word and also identifying and mapping contextual dependencies of each word in the text/question.
Matching of tokens between input text and Graph-based artifacts will be based on N-Gram i.e., An n-gram can be as short as a single word (unigram) or as long as multiple words (bigram, trigram, etc.). These n-grams capture the contextual information and relationships between words in each text. Weightage is given to the highest gram of token matching. Ex: Meters (1-gram) Vs. Meter Issues(bi-gram) etc.
Token Identification has 2 parts a) LLM based Token Identification and b) Value-based search facilitated by Elastic Search (Non-LLM Flow)
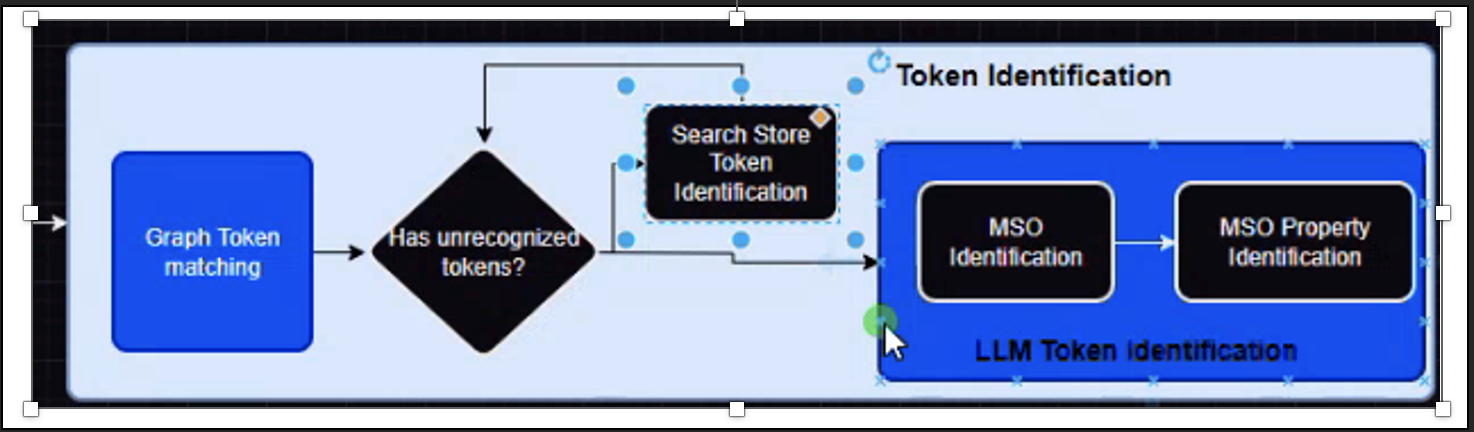
a) Once all the token matching is complete, any unrecognized tokens are once again sent to the LLM Token Identification block for Ex: In the query: "Show all meters which are manufactured by Neptune”: The LLM Token Identification block will have 2 components a) mso Identifier b) mso property identifier. Meters will be matched to an MSO from the list of all MSOs. Similarly, once the MSO is matched, all the properties of the MSO are sent to be matched with the unrecognized tokens in question. This will ensure that the manufactured by token will be mapped to the graph "manufacturer" property in our Ontology.

b) Elastic Search is invoked when the unrecognized tokens contain Product Description or names or values as part of the Easy Answers question. Ex: Show all product details that have Garnier Shampoos. In this case, Garnier Shampoos are product names or descriptions and can be searched via Elastic Search. Once the unrecognized token is resolved, the flow completes and picks the next unrecognized token.
Prompt Generation
This step is critical as the output of this step is an instructionally and structurally accurate and well-formed prompt which will help in optimizing the DB query thereby increasing the likelihood of retrieving the anticipated response. The assembly of the prompt considers information across various Question Tags like "Temporal (Date), Spatial (properties related to State, County, Geometry, etc.), Negated (if the query contains Show all meters which don't have any issues), Value Synonyms (Surf City USA is a synonym of San Diego), Default MSO properties". These tags represent Examples and Instructions that are used to provide specificity to Prompt Generation.
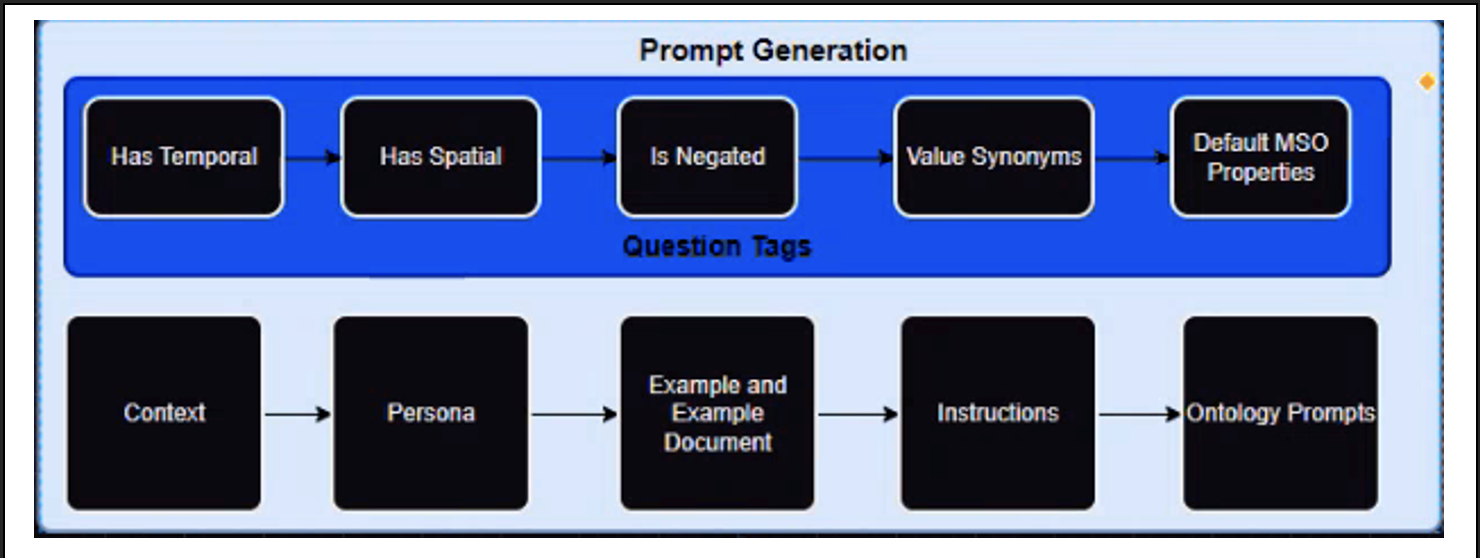
Actual Prompt Creation
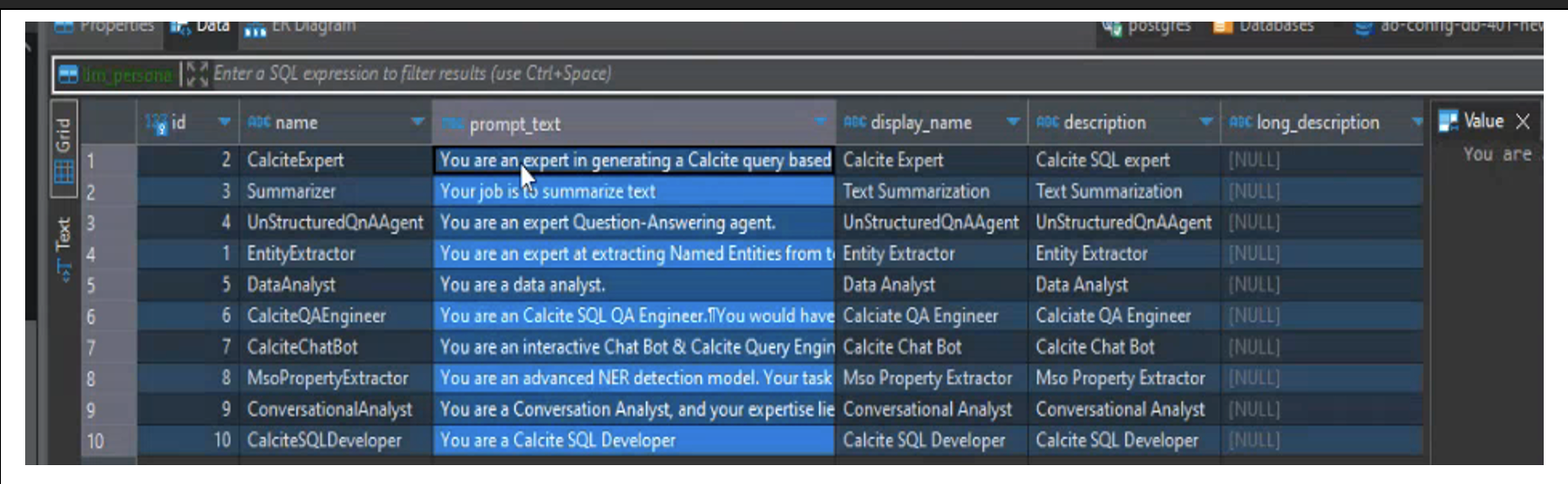
Starting with the use case we are solving i.e. the Context. Next is leveraging the persona which is related to the SME i.e. if the question is Legal, we would like to leverage an assistant who understands the legal lingo, and is able to provide context specific instructions for prompt creation, etc. All these personas are configurable, and for Easy Answers, these are configured in the DB. In short Persona is related to the LLM Persona for the problem which is being solved rather than the person who is solving the problem.
For any prompt to be complete, it is necessary to provide In-Context examples to provide guidance. This is an approach that in the LLM world is called In-Context Learning (ICL) with the help of Zero-shot (no examples) or Few Shot (with a few examples). An example of ICL could be explained as: Assuming we are trying to Identify the sentiment of a product review. Here, we provide an example of Positive, Negative, and Neutral Sentiment from a bunch of reviews: a) I loved using the product - Sentiment: Positive b) The product doesn't meet my expectations, and I had a frustrating experience using the product Sentiment: Negative c) The product met the basic needs, and I might continue to use the product. Sentiment: Neutral.
Specifically for Easy Answers, these examples are based on a fictitious ontology (generic ontology) which will serve as the few shot examples for prompts. Instructions on the other hand are derived from all the Question Tags (Temporal, Spatial, Value synonyms, etc.), and pass all the query/relative functions or default mso properties, traits, etc. to the LLM to prepare the LLM with a set of instructions.
Ontology Prompts are designed specifically for a given ontology. This will be implementation-specific.

Query Generator - N Threads
When you run the query multiple times, on one of the occasions, it is supposed to give you the right answer. This uses a ReAct1 (Reasoning and Acting) framework, where the system iteratively runs the query multiple times. This output is then passed to the decoder to identify the best possible query based on a probability distribution score.
An important learning from the research and tests was that limiting the scope of the question to optimize the response i.e. lesser we ask the LLM to do, the better the performance (run-time and accuracy of responses).
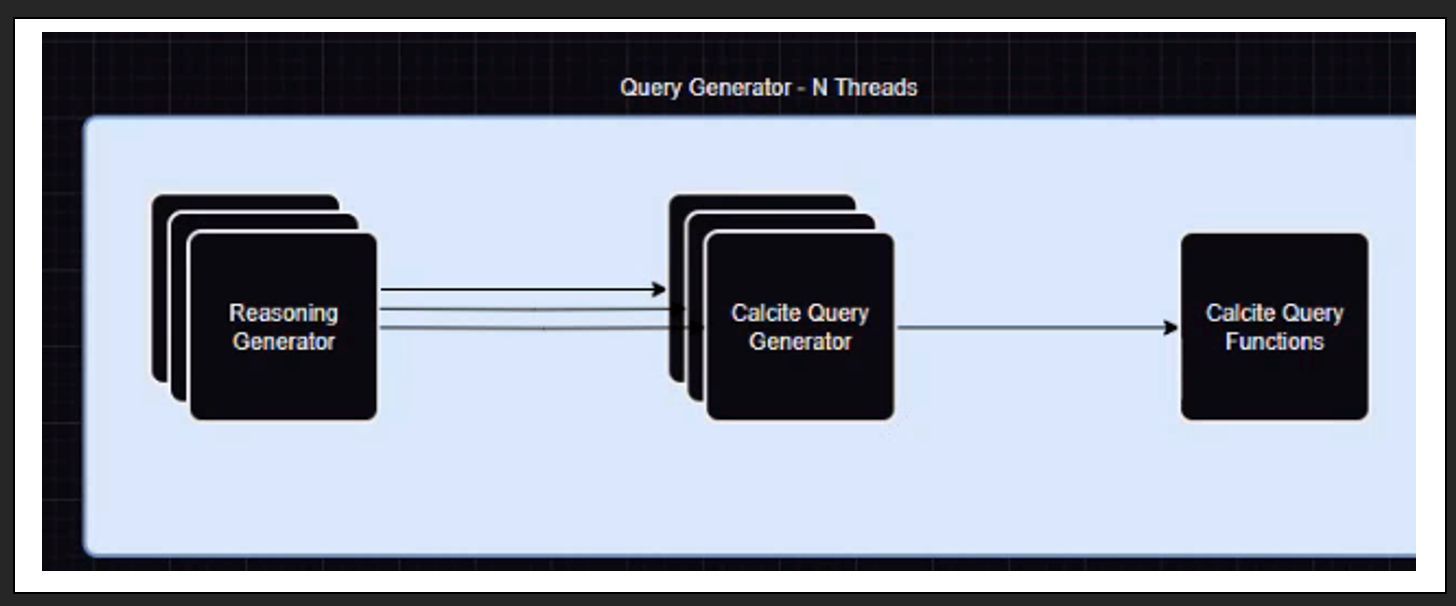
The Reasoning Generator
The Reasoning Generator takes the query and using Chain of Thoughts2 i.e. if we ask the LLM to think and generate a textual response to a question, LLM performs much better as it uses a reasoning approach2. Once the reasoning is generated, it is passed to the Calcite Query Generator, which will generate the question by looking at the answer (loop back mechanism). This process will iterate for N-Threads (by default, it is set to 1 within the Ontology Composer), as part of a self-consistency approach to reach the best possible answer. Choosing the best answers is based on instructions around criteria/parameters (is the query syntactically and semantically correct, have you followed all the rule synonyms related to the question, etc.), for picking the best query, and is handled by the LLM-based Query Validator.
Calcite Query Functions
The Calcite Query Functions are primarily around date functions like "show all meters in the last 2 weeks or 3 months etc.). Now that we have completed the reasoning and generation of the query, the next step is to validate if the query is correct.


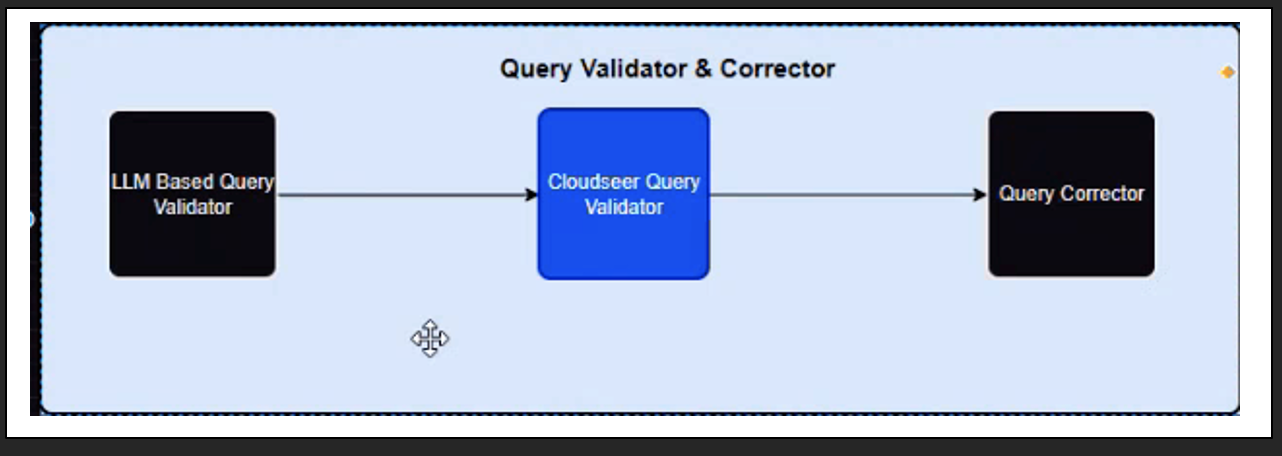
Query Validator & Creator
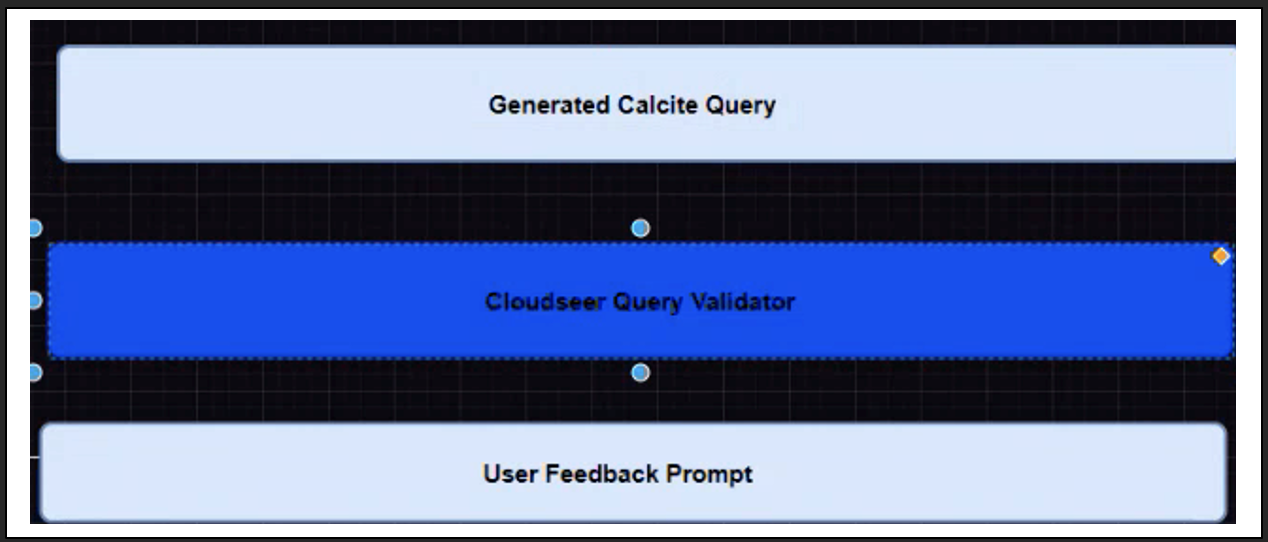
This block validates if the query is correct, and not correct as well. Once the most appropriate query is identified, the query is passed to Cloudseer Query Validator for the final step of validation. If the Cloudseer validator throws any errors, the error is fed to another LLM namely, Query Corrector with whatever feedback we have received from the Cloudseer Query Validator and the LLM-based Query Validators. Query Corrector will use this feedback to correct the error and output the corrected query.
Generated Calcite Query / Cloudseer Query Validator / User Feedback Prompt
Finally, there is another set of Validators to ensure the corrected query is displayed to the user. In addition, in case the user identifies that the generated response is incorrect, they have a feedback mechanism which is the Human Feedback loop to re-submit the query with additional user feedback to the Token Identification block, and the whole process re-starts.