Ontology - Sourcing
Intended audience: ANALYSTS DEVELOPERS ADMINISTRATORS
AO Platform: 4.3
Overview
This section contains the configuration of the Ontology’s data source relative to the availability of data in a tiered storage infrastructure. From the 4.1 release of the AO Platform, the Ontology now “owns” the data source(s) compared to previous releases where data sources were associated with the individual MSOs in an Ontology. This provides multiple benefits, including a) a more flexible way to switch data sources when multiple data sources are created and used between a development and a production environment, b) performance when loading tables from database environments with hundreds of schemas and/or thousands of tables, and c) a configuration is federated to access multiple underlying data sources via a single data source access point.
There are two types of configurations:
Access to Data Sources via Metastore Cache. See Adding Schemas and Tables to Metastore Cache.
Access to Data Sources via a Federated Configuration. See Ontology - Federated Data.
Tiers
Hot - data is accessed frequently, often based on an in-memory data source
Warm - data is accessed less frequently, typically retrieved from mid-tier database storage
Cold - data is only accessed sporadically, and retrieval may be delayed as data may be in archived storage or a cloud-based data lake
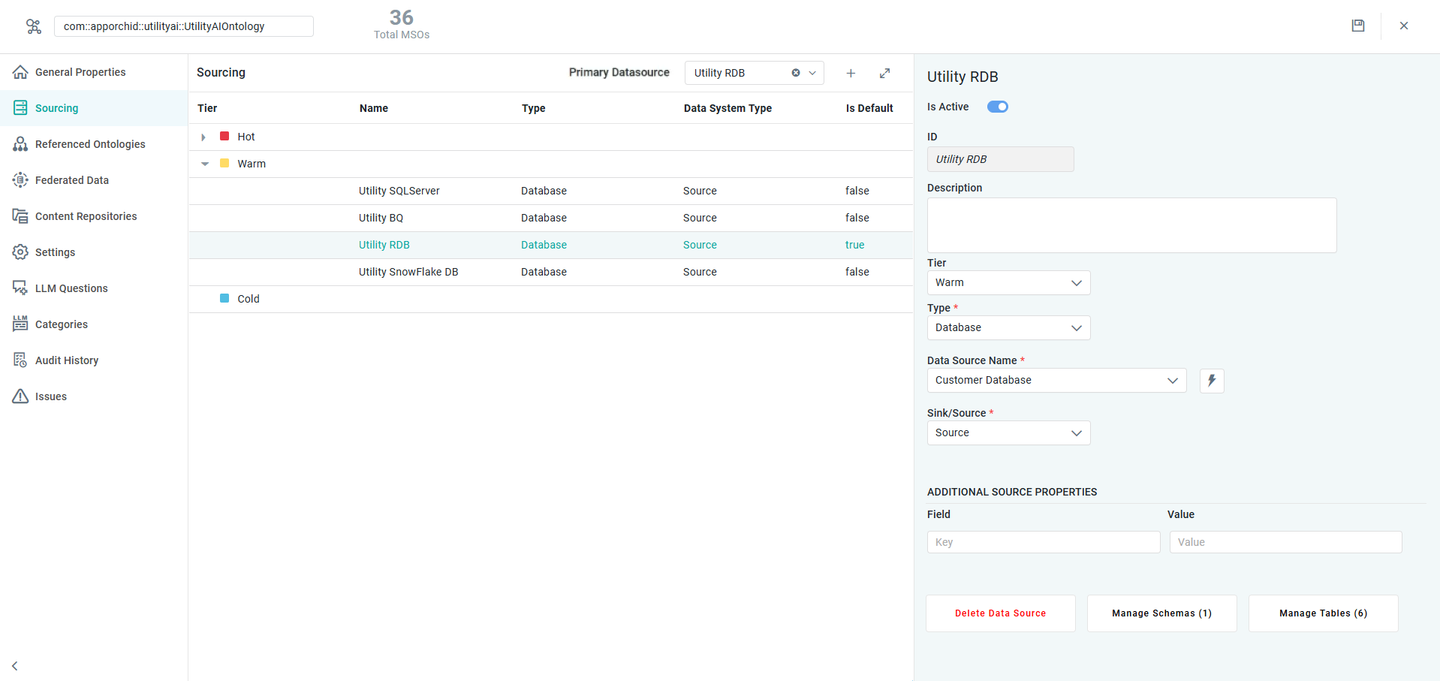
User Actions
Primary Data Source - select from the dropdown to make a data source the default to be used by the MSOs created for the Ontology.
Add (+) - select to add the properties.
Expand – expands/collapses the properties section when the property details are shown on the right side of the screen.
Delete Data Source - deletes all configuration details for the selected Data Source.
Manage Schemas - select to Manage Schemas available for the selected Data Source. See details for Adding Schemas and Tables to Metastore Cache.
Manage Tables - select to Manage Tables available for the selected Data Source. See details for Adding Schemas and Tables to Metastore Cache.
Data Source Properties
The Property Details panel is used to configure the details for each property of the MSO's data source relative to the availability of data in a tiered storage infrastructure.
Label | Description |
|---|---|
Name | The Name field is the display name of the data source. |
Is Active | The Is Active property allows an Ontology Data Source to be created and configured but also made inactive. This is useful if multiple data sources are created and configured for the Ontology eg. for use during development vs. being used in a production environment. Simply enable the data source to be used with the Is Active property. |
ID | This is the internal ID for an Ontology Data Source. This field is read-only. |
Description | The Description field displays a brief description of the data source. |
Tier | The Tier dropdown field displays the list of storage classification options:
|
Type | The Type dropdown field displays the list of data source types from which the data is retrieved, ie, Database, Generic, Pipeline. |
Sink/Source | The Sink/Source dropdown allows the user to select whether to use the data source as either a data Source, Sink, or both (Source and Sink). |
If Type = Database | |
| The Data Source Name dropdown allows the user to select the database name from where the data is retrieved. |
| A repeater section of Key / Value pairs to show in the table. |
If Type = Generic | |
| Select between CSV, Excel, Shapefile, GeoJSON, XML, Large Excel, Solr, Google BigQuery, or Neo4j for the Source/Sink. |
| |
| A repeater section of Key / Value pairs to show in the table. |
| A predefined list of keys that helps configure the Generic data source. Select and configure only the keys that are required to retrieve the data. |
| The value content relating to the Key field selected. |
If Type = Pipeline | |
| Click the Search icon to select from existing Pipelines to use as the Source Pipeline. |
| Click the Search icon to select from existing Pipelines to use as the Sink Pipeline. |