BoW Entity Extractor
Intended audience: ANALYSTS DEVELOPERS ADMINISTRATORS
AO Platform: 4.3
Overview
This topic contains the Parameters configuration section of the BoW (Bag of Words) Entity Extractor Strategy.
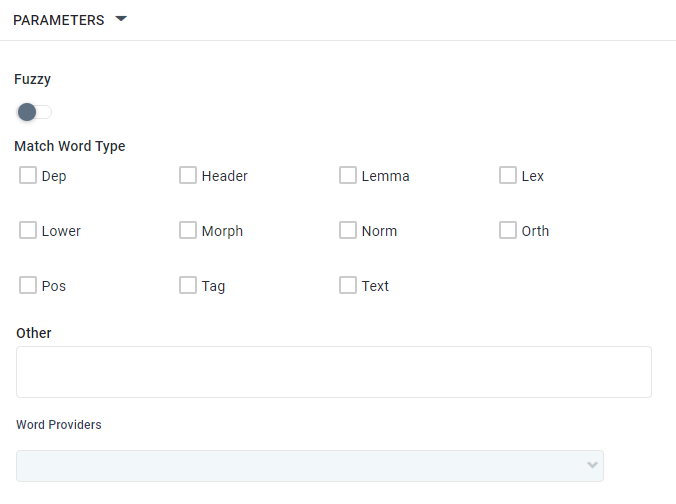
Properties
Label | Description |
|---|---|
Fuzzy | |
Match Word Type | See table below. |
Word Providers |
Match Word Types
Display Name Label | Description |
Dependency (DEP) | Syntactic dependency relation. |
Head of token (HEAD) | Syntactic head of the token. |
Lemma (LEMMA) | Base form of the token, with no inflectional suffixes. |
Lexeme (LEX) | The underlying lexeme. |
Lowercase (LOWER) | Lowercase form of the token. |
Morphological Annotation (MORPH) | Morphological Annotation. |
Normalized token (NORM) | The token’s norm, i.e. a normalized form of the token text. |
ID of Token (ORTH) | ID of the verbatim text content. |
Part-of-Speech (POS) | Coarse-grained part-of-speech from the Universal POS tag set. |
Fine-grained part-of-speech (TAG) | Fine-grained part-of-speech. |
Text (TEXT) | Verbatim text content. |
Also see Testing Strategies.