ML Algorithms > [Algorithm Name]
Intended audience: DATA SCIENTISTS DEVELOPERS ADMINISTRATORS
AO Platform: 4.3
Overview
This topic only relates to ML Models of Type: Regression, Classification, and Clustering. For Bayesian ML Models, the ML Algorithms page is not available; instead, the user will see a Learning Algorithm page. See Learning Algorithm.
The AO Platform is provided with the following out-of-the-box ML Algorithms that can be used to create Models. Many more are expected to be added over time. For a full description of the ML Algorithms and their technical details, see > https://scikit-learn.org/stable/.
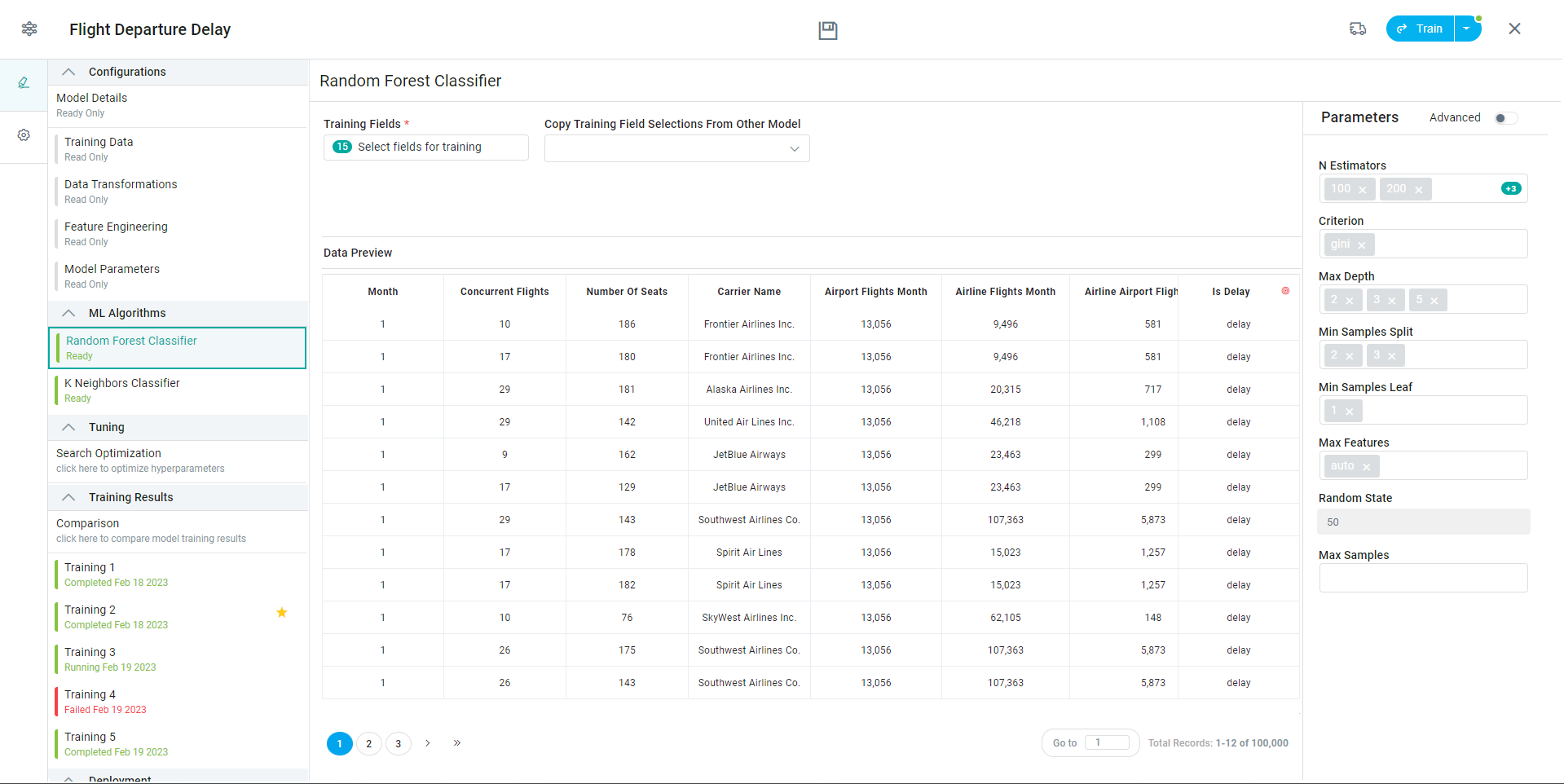
All properties are prepopulated with the default values - see links for each of the ML Algorithms in the table below.
ML Algorithm Types
Regression
ML Algorithms | Category | Description | Additional Documentation |
|---|---|---|---|
Lasso Regression | Supervised Learning | Linear Model trained with L1 prior as regularizer (aka the Lasso). Technically, the Lasso model is optimizing the same objective function as the Elastic Net with | |
Linear Regression | Supervised Learning | LinearRegression fits a linear model with coefficients w = (w1, …, wp) to minimize the residual sum of squares between the observed targets in the dataset, and the targets predicted by the linear approximation. | |
Logistic Regression | Supervised Learning | This class implements regularized logistic regression using the ‘liblinear’ library, ‘newton-cg’, ‘sag’, ‘saga’, and ‘lbfgs’ solvers. Note that regularization is applied by default. It can handle both dense and sparse input. Use C-ordered arrays or CSR matrices containing 64-bit floats for optimal performance; any other input format will be converted (and copied). | |
Ridge Regression | Supervised Learning | This model solves a regression model where the loss function is the linear least squares function and regularization is given by the l2-norm. This estimator has built-in support for multi-variate regression (i.e., when y is a 2d-array of shape (n_samples, n_targets)). | |
Support Vector Regression (SVR) | Supervised Learning | The free parameters in the model are C and epsilon. The implementation is based on libsvm. The fit time complexity is more than quadratic with the number of samples, which makes it hard to scale to datasets with more than a couple of 10000 samples. |
Classification
ML Algorithms | Category | Description | Additional Documentation |
|---|---|---|---|
ADA Boost Classifier | Supervised Learning | An AdaBoost classifier is a meta-estimator that begins by fitting a classifier on the original dataset and then fits additional copies of the classifier on the same dataset but where the weights of incorrectly classified instances are adjusted such that subsequent classifiers focus more on difficult cases. This class implements the algorithm known as AdaBoost-SAMME. | |
Decision Tree Classifier | Supervised Learning | A class capable of performing multi-class classification on a dataset. | |
K Neighbors Classifier | Supervised Learning | Classifier implementing the k-nearest neighbors vote. | |
Random Forest Classifier | Supervised Learning | A random forest is a meta estimator that fits several decision tree classifiers on various sub-samples of the dataset and uses averaging to improve the predictive accuracy and control over-fitting. The sub-sample size is controlled with the | |
Support Vector Classifier (SVC) | Supervised Learning | The implementation is based on libsvm. The fit time scales at least quadratically with the number of samples and may be impractical beyond tens of thousands of samples. For large datasets, consider using The multiclass support is handled according to a one-vs-one scheme. | |
XG Boost Classifier | Supervised Learning | eXtreme Gradient Boosting for classification. GB builds an additive model in a forward stage-wise fashion; it allows for the optimization of arbitrary differentiable loss functions. In each stage, |
Clustering
ML Algorithms | Category | Description | Additional Documentation |
|---|---|---|---|
DBSCAN Clustering | Unsupervised Learning | Perform DBSCAN clustering from a vector array or distance matrix. DBSCAN - Density-Based Spatial Clustering of Applications with Noise. Finds core samples of high density and expands clusters from them. Good for data that contains clusters of similar density. | |
K Means Clustering | Unsupervised Learning | The K Means algorithm clusters data by trying to separate samples in n groups of equal variance, minimizing a criterion known as the inertia or within-cluster sum-of-squares (see below). This algorithm requires the number of clusters to be specified. It scales well to many samples and has been used across a large range of application areas in many different fields. |