Intended audience: developers administrators
AO Platform: 4.5
Architecture & Interoperability
What are the key components in the AO Platform tech stack deployed on Kubernetes (EKS) on AWS.
The AO Platform is a single-tenant web application, where each customer is deployed into a logically isolated environment (AWS account/VPC/namespace).
Key components:
-
Frontend: Web UI served behind AWS Application Load Balancer (ALB).
-
Backend: REST APIs running as containerized services on Amazon EKS.
-
Database: Amazon RDS (PostgreSQL) in Multi-AZ configuration.
-
Messaging: AWS ActiveMQ for messaging and notifications.
-
Caching: Redis, an in-memory cache for performance and scalability.
-
Federation: Trino federated database for running federated queries from multiple data sources.
-
Search: Amazon OpenSearch for document search.
-
Storage: Amazon S3 for file/object storage to store documents and files.
-
Observability: Amazon CloudWatch, Prometheus/Grafana stack for metrics and dashboards.
What Deployment Models are supported?
Each tenant has an isolated Kubernetes namespace and its own provisioned managed and unmanaged services. Infrastructure is provisioned and managed using Terraform and deployment through Helm Charts.
How does the AO Platform scale?
All components of the AO Platform scale horizontally to support variable workloads:
-
App services-horizontal scaling: All services running on EKS are scalable by increasing the ReplicaSets count in the Helm Chart configuration, driven by the Horizontal Pod Autoscaler based on set CPU/memory thresholds.
-
Database: RDS Multi-AZ for high availability. Read replicas for read-heavy workloads.
-
Queue/Messaging: multiple queues/topics in Amazon Active MQ for parallelism. Consumers must scale horizontally on EKS based on queue depth.
-
Federation: Trino worker nodes horizontally scale based on the query complexity and Joins.
What are the SLAs for Availability & Uptime?
Below are the SLAs for the AO Platform hosted and managed by App Orchid:
For each environment in production:
-
Monthly availability target: ≥ 99.5%
-
Quarterly availability target: ≥ 99.9%
Availability is measured as the percentage of time the production APIs are able to return successful responses, excluding:
-
Approved and pre-announced maintenance windows.
-
Force majeure events.
For self-hosted customers, we can share the best practices and assist in refining the system and the processes.
What’s the supported Backups and Replication policy?
-
Amazon RDS: Automated backups enabled with at least 35 days of retention or as mandated by the customer. Point-in-time recovery is enabled to meet RPO.
-
Amazon S3: Versioning enabled for critical buckets as required. Lifecycle policies for long-term retention and archival.
What is the AO Platform Disaster Recovery (DR) policy?
We generally follow best practices recommended by the cloud provider. Below is the DR plan that we follow for the systems hosted in our Cloud. We can work with on-prem/self-hosted customers to tailor to specific needs.
A secondary AWS region is defined for DR (eg, primary: us-east-1, DR: us-west-2).
For each tenant:
-
Infrastructure can be recreated in the DR region using IaC (Terraform).
-
RDS snapshots and S3 data can be restored/replicated to the DR region.
DR tests are executed at least annually, demonstrating:
-
Ability to restore services within the Recovery Time Objective (RTO).
-
Data consistency within Recovery Point Objective (RPO).
RTO
-
Critical services: ≤ 4 hours.
-
Non-critical services: ≤ 24 hours.
RPO
-
Transactional data (RDS): ≤ 15 minutes.
-
Configuration & metadata: ≤ 1 hour.
Interoperability & Portability (Open Standards)
Open Standards
-
APIs use:
-
REST/JSON
-
Documented using OpenAPI/Swagger.
-
-
Authentication and authorization leverage standard protocols:
-
OAuth2 / OIDC and SAML.
-
Portability
-
Data Portability: Data portability is not applicable, as data stays in your systems
-
Ontology Portability:
-
Between the AO Platform instances. A robust transport mechanism can move Ontology between servers with all the enrichment.
-
Between the AO Platform and third-party systems. Ontology can be exported as an OWL/RDF and can be imported into the target system.
-
Other
How does App Orchid’s semantic layer integrate with existing enterprise data architectures like data lakes, data warehouses, ERP systems, and legacy platforms?
The AO Platform connects with data sources primarily using JDBC drivers, with SQL pushdown. We use Trino to enable federated queries and Calcite as the data management framework. We generally tap into the curated zones, typically Silver or Gold, in the data lakes.
For ERP and Cloud native systems, we have the ability to fetch delta records using CDC periodically and store them in Iceberg. We use this approach for API-centric data sources, such as SFDC or ServiceNow.
Can you describe the underlying architecture for the knowledge graph and natural language querying? Is it cloud-native and containerized for scaling?
Our platform is hyperscale-agnostic and LLM-agnostic. We use ArangoDB as our graph database to store the Ontology and metadata. Actual data is not moved into the graph but retrieved dynamically from the data stores at runtime in the context of the question being answered. All platform components are containerized and deployed using Helm charts.
How modular is the platform? Can we deploy certain capabilities (eg, Easy Answers™) independently of the entire suite?
Our Semantic Knowledge Graph is the foundation for all the other components, which makes it mandatory. Additional services can be deployed on a need basis.
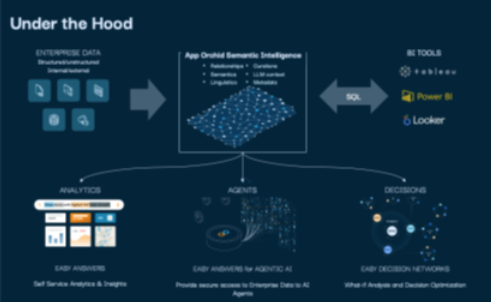
How do you handle hybrid or multi-cloud architectures where some systems are on-prem, and others are in the cloud?
If there are connectivity and low latency, we can access both cloud-native and on-prem data sources. Where there are latency issues, we can do some lightweight caching.
Go to all FAQs.
Contact App Orchid | Disclaimer